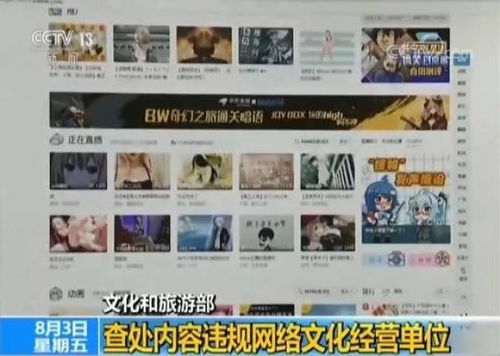
文旅部強化農(nóng)村上網(wǎng)服務場所監(jiān)管,促進網(wǎng)絡文化健康經(jīng)營

為加強農(nóng)村地區(qū)上網(wǎng)服務場所管理,保障未成年人權益,促進網(wǎng)絡文化市場健康有序發(fā)展,文化和旅游部近期發(fā)布《關于進一步加強農(nóng)村地區(qū)上網(wǎng)服務場所監(jiān)管 規(guī)范網(wǎng)絡文化經(jīng)營的通知》,對相關工作作出明確部署。
隨著互聯(lián)網(wǎng)普及和數(shù)字鴻溝逐步彌合,農(nóng)村地區(qū)上網(wǎng)服務場所(俗稱“網(wǎng)吧”)已成為滿足當?shù)厝罕姡貏e是外出務工人員返鄉(xiāng)、青少年學生等群體文化娛樂需求的重要場所。部分農(nóng)村地區(qū)上網(wǎng)服務場所存在經(jīng)營管理不規(guī)范、違規(guī)接納未成年人、存在安全隱患等問題,影響了行業(yè)的健康發(fā)展和社會秩序。
對此,文化和旅游部要求各級文化和旅游行政部門,需嚴格依據(jù)《互聯(lián)網(wǎng)上網(wǎng)服務營業(yè)場所管理條例》等法律法規(guī),強化屬地監(jiān)管責任。重點舉措包括:
一、嚴格市場準入,優(yōu)化布局規(guī)劃。 嚴格農(nóng)村地區(qū)上網(wǎng)服務場所的設立審批,加強總量和布局調(diào)控,鼓勵其在鄉(xiāng)鎮(zhèn)、集市等人口聚集區(qū)規(guī)范發(fā)展,避免無序競爭。推動上網(wǎng)服務場所改善環(huán)境、提升服務,向兼具社交、休閑、數(shù)字技能培訓等多功能的綜合性文化服務場所轉(zhuǎn)型升級。
二、強化內(nèi)容監(jiān)管,規(guī)范經(jīng)營行為。 嚴格落實上網(wǎng)實名登記制度,堅決杜絕為未成年人提供上網(wǎng)服務。加強對場所內(nèi)網(wǎng)絡文化內(nèi)容的巡查,嚴禁傳播含有危害國家安全、宣揚淫穢色情、賭博暴力等法律法規(guī)禁止內(nèi)容的信息。督促經(jīng)營者依法經(jīng)營,不得利用網(wǎng)絡游戲或其他網(wǎng)絡文化產(chǎn)品進行賭博或變相賭博活動。
三、壓實主體責任,排查安全隱患。 要求上網(wǎng)服務場所經(jīng)營者嚴格落實安全生產(chǎn)和消防安全主體責任,定期排查電路、消防設施等方面的安全隱患,確保場所安全。加強對場所內(nèi)疫情防控工作的指導,保障消費者和員工健康。
四、加強執(zhí)法檢查,形成監(jiān)管合力。 各級文化和旅游行政部門將加大日常巡查和“雙隨機、一公開”抽查力度,特別是在節(jié)假日、寒暑假等重點時段,增加檢查頻次。會同公安、市場監(jiān)管、消防救援等部門開展聯(lián)合執(zhí)法,對違規(guī)經(jīng)營行為依法予以查處,情節(jié)嚴重的將吊銷《網(wǎng)絡文化經(jīng)營許可證》。鼓勵社會監(jiān)督,暢通舉報渠道。
五、推動行業(yè)自律,提升服務質(zhì)量。 引導和支持行業(yè)協(xié)會在農(nóng)村地區(qū)開展活動,制定行業(yè)規(guī)范,加強從業(yè)人員業(yè)務和法規(guī)培訓,倡導守法誠信經(jīng)營。鼓勵上網(wǎng)服務場所積極承擔社會責任,參與鄉(xiāng)村公共數(shù)字文化服務,有條件地開展面向農(nóng)民的互聯(lián)網(wǎng)應用技能普及活動。
此次加強監(jiān)管旨在將農(nóng)村上網(wǎng)服務場所納入更加規(guī)范的管理軌道,保護廣大農(nóng)村網(wǎng)民特別是青少年的合法權益,凈化農(nóng)村網(wǎng)絡文化環(huán)境,并引導其發(fā)揮積極作用,服務于鄉(xiāng)村文化振興和數(shù)字鄉(xiāng)村建設。文旅部將持續(xù)關注政策落實情況,確保農(nóng)村網(wǎng)絡文化市場清朗有序,為農(nóng)村居民提供健康、有益的網(wǎng)絡文化消費空間。
如若轉(zhuǎn)載,請注明出處:http://www.ssjrx.cn/product/65.html
更新時間:2026-06-09 15:55:48